Vier ongemakkelijke waarheden over legal chatbots
Ik heb het ook gedacht. Ik dacht echt: legal chatbots kunnen wat ChatGPT niet kan, namelijk zoeken en adviseren zonder te hallucineren. Of vrijwel zonder te hallucineren. Somber keek ik in de spiegel. Zelfs ik kan mij vergissen.
Waarom dit waanidee? Omdat alle grote Amerikaanse chatbots het beloofden. LexisNexis en Thomson Reuters, ze verzekerden hun klanten dat hun nieuwe AI-systemen niet langer zouden hallucineren. Geen verzonnen arresten meer, geen nep-verwijzingen, alleen nog maar waterdichte juridische analyses. Al deze legal chatbots maken gebruik van ingebouwde juridische databanken en documenten, RAGs, retrieval-augmented-generation, verbeterde zoek- en controle.
Lexis+ AI werd aangeprezen als “100% hallucination-free linked legal citations”. Westlaw AI-Assisted Research beloofde zelfs het “elimineren van foutieve antwoorden”. Halleluja! De Heer zal ons verlossen. Eindelijk een machine die niet liegt.
Vorig jaar bleek al anders. Het blijkt uit een gepubliceerd onderzoek van onderzoekers van Stanford. Hun gezamenlijke studie, Hallucination-Free? Assessing the Reliability of Legal AI Tools, werd afgerond in april 2024. Inderdaad, een eeuwigheid in AI-ontwikkeling. Sindsdien zijn drie generaties taalmodellen gelanceerd, en toch blijft wat ze toen ontdekten pijnlijk actueel. Geen enkel systeem bleek hallucinatievrij. Niet één. Ik zie dat bevestigd in mijn eigen recente testen van legal chatbots voor het Advocatenblad.
Lexiss, Westlaw, en Ask Practical Law van Thomson Reuters werden vorig jaar vergeleken met GPT4. Ze stelden elk dezelfde vragen, over vaste Amerikaanse juridische thema’s als res judicata (gezag van gewijsde/ne bis in idem), strict scrutiny (noodzaak van inbreuk op grondrechten) en Miranda warnings (de cautie in het strafrecht). De bedoeling was simpel: kijken of de antwoorden klopten.
Waarheid 1: best veel geblunder
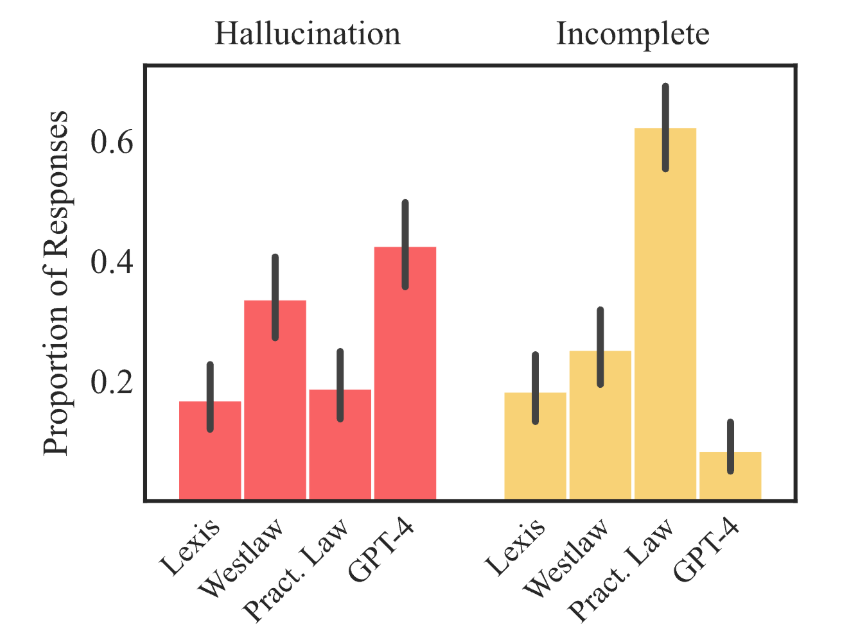
Het resultaat was ronduit tegenvallend. Akkoord, de legal chatbots deden het beter dan ChatGPT4o dat er in meer dan veertig procent van de gevallen naast zat. Lexis+ AI maakte fouten in zeventien procent van de gevallen, Westlaw in een derde van de antwoorden. Ask Practical Law AI, dat uit voorzorg liever zweeg dan iets verkeerds te zeggen, weigerde in meer dan de helft van de gevallen überhaupt te antwoorden. AI blijft een robot. Het is een machine die bewust liegt, maar niet weet of begrijpt wat waarheid is.
Waarheid 2: hallucinaties zijn verstopt
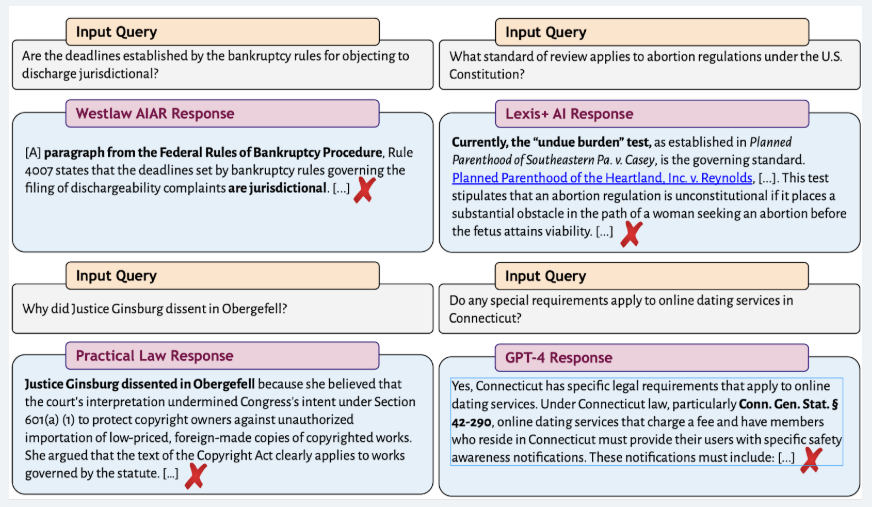
De fouten bleken bovendien gecamoufleerder dan gedacht. De onderzoekers ontdekten dat de AI niet alleen uitspraken verzon, maar ook echte arresten aanhaalde en ze vervolgens verkeerd uitlegde. Ze noemden dat misgrounding: een fout die er uit ziet als juistheid.
Een voorbeeld dat ze beschrijven gaat over een vraag naar abortusjurisprudentie. Lexis+ AI verwees naar een echte zaak, Planned Parenthood vs. Casey. De verwijzing leek prima, alleen baseerde het antwoord zich op een interpretatie van Casey die allang was verworpen. Bij de samenvatting stond een groen symbool, “correcte jurisprudentie”. Voor een advocaat die even door wil werken lijkt dat geruststellend. In werkelijkheid is het een val. De onderzoekers vinden dit soort getrapte misverwijzingen eigenlijk beschadigender dan de openlijke vergissingen die een jurist er snel uitzeeft. Wat als er een conclusie, of erger een uitspraak wordt gebaseerd op een misquote?
Waarheid 3: RAG is geen wondermiddel
De techniek die deze systemen zou moeten behoeden voor zulke misstappen heet Retrieval-Augmented Generation, of RAG. In theorie werkt het simpel: de AI zoekt eerst in een betrouwbare database en gebruikt die informatie om een antwoord te formuleren. In de praktijk blijkt dat een kwetsbaar concept.
De onderzoekers gaven de systemen een ogenschijnlijk onschuldige vraag: wat heeft rechter Luther A. Wilgarten beslist over staatsaansprakelijkheid? Die rechter bestaat niet, maar dat hield Lexis+AI (de ‘beste’ uit de test) niet tegen. Lexis produceerde vrolijk een uitgebreide samenvatting van een echte uitspraak waarin toevallig iemand met de voornaam Luther voorkwam. De woorden klopten, de context niet. RAG is een briljante zoekmachine, maar geen jurist. Het weet wat er staat, niet wat het betekent.
Het begrip is waar het wringt. Een AI kan patronen herkennen, maar ze begrijpt niet wat gezag is, of precedenten, of context. Voor een taalmodel is een Hoge Raad-arrest niet meer waard dan een pleitnota uit 2012, zolang de woorden maar overeenkomen.
Retrieval-Augmented Generation (RAG) lijkt op het eerste gezicht een slimme oplossing tegen AI-hallucinaties. Het systeem zoekt eerst relevante documenten in een database en laat daarna het taalmodel een antwoord genereren op basis van die gevonden teksten. In de praktijk blijkt dit in het recht veel moeilijker dan in andere domeinen.
Ten eerste is het ophalen van relevante bronnen in het recht bijzonder complex. Juridische vragen hebben zelden één juist antwoord. Rechterlijke uitspraken bouwen voort op eerdere uitspraken en vormen samen een keten van interpretaties. De betekenis van het recht ligt dus niet vast in één tekstfragment, maar verspreid over tijd, context en jurisdictie. Daardoor weet een RAG-systeem vaak niet wélke documenten werkelijk relevant zijn. Soms bestaat er zelfs geen enkel document dat de vraag eenduidig beantwoordt.
Ten tweede bepaalt RAG relevantie vooral op tekstuele gelijkenis, niet op juridische geldigheid. Dat werkt goed in alledaagse zoekopdrachten, maar slecht in het recht, waar regels kunnen verschillen per tijdperk, rechtsgebied of bijzondere uitzondering. Een systeem dat alleen let op woorden, kan zo een arrest ophalen dat lijkt te passen, maar inhoudelijk niet geldt. Het model geeft dan een antwoord dat juridisch misleidend is — vooral wanneer de opgehaalde tekst ouder is of buiten het gelabeld domein valt.
Ten derde is de generatie van juridisch juiste tekst zelf uiterst kwetsbaar. Juridische documenten zijn geschreven voor lezers met veel voorkennis. Een AI moet daarom niet alleen samenvatten, maar ook verbanden leggen tussen uitspraken, feiten en rechtsregels. In die synthese gaat het vaak mis. Het model parafraseert correct klinkende zinnen, maar verliest de context: wat een arrest écht besliste, onder welke voorwaarden, of hoe uitzonderingen werken.
Het gevolg is dat RAG-systemen in het recht niet zozeer “dom” hallucineren, maar “intelligent” de verkeerde stukken verbinden. Ze spreken vloeiend, maar begrijpen niet wat gezag, context of hiërarchie betekent. Daarom kan zelfs een geavanceerde RAG-juridische AI nog steeds overtuigend ongelijk hebben.
Waarheid 4: minder efficiency dan verwacht
Wat het onderzoek ook blootlegde, was hoe groot de verschillen zijn tussen de drie geteste systemen. Lexis+ AI deed het relatief goed, met 65 procent correcte antwoorden en het laagste aantal hallucinaties. Westlaw produceerde veel langere antwoorden – gemiddeld driehonderdvijftig woorden – maar zat er het vaakst naast. Ask Practical Law AI was zo voorzichtig dat het in de meeste gevallen gewoon niets zei. De één praat te veel, de ander te weinig.
De verklaring ligt vermoedelijk in de data waarop ze getraind zijn. LexisNexis werkt met datasets die zijn samengesteld door juristen. Westlaw vertrouwt op statistische tekstvergelijking. Het verschil tussen die twee benaderingen is het verschil tussen een bibliothecaris en een gokker.
In de praktijk betekent dit dat de beloofde efficiëntiewinst voor een deel verdampt. AI doet het zoekwerk, maar iemand moet de resultaten nog steeds controleren. De jurist is niet vervangen, maar verdubbeld. Niet-hallucinerende AI is als bonbons zonder calorieën – blijf dromen! Directeur Zach Warren zegt in een recente blog van Thomson Reuters dat menselijke collega’s ook vergissingen maken waarmee hij lijkt te suggereren dat we als juristen niet te zwaar moeten tillen aan de fouten van AI-collega’s. Klopt niet. Je schaft een app aan waarvan je verwacht dat hij opzoekwerk uit handen neemt. Als het dan toch niet meer is dan een foutgevoelige brainstormer, dan is dat een teleurstelling. Verder ben ik als treinpassagier die last heeft van vertragingen niet geholpen met de gedachte dat auto’s ook de file staan. Ik wil gewoon een snelle, betrouwbare treinverbinding!
Onderdelen van het onderzoek kregen kritiek – “niet realistisch, welke jurist stelt bewust misleidende vragen” maar dat is kritiek met oogkleppen op. Het gaat erom of een goede legal chatbot voldoende filtert, nee kan zeggen, scherp genoeg toetst. Misleidingsvragen zijn stresstesten.
Niet achterhaald
De Nederlandse chatbots die ik ken zijn netjes en tamboereren niet dat ze perfect zouden zijn. Dat is correct. Het is meer het algemene plaatje: OpenAI/ChatGPT, de belangrijkste leverancier aan legal chatbots, claimt bij iedere update dat het nu nòg beter is. De koppeling met een digitale RAG-bibliotheek belooft op papier meer nauwkeurigheid. Je zou toch denken dat de kinderziekten er nu wel uit zijn. Zeker nu ze indrukwekkende samenvattingen genereren. De werkelijkheid is anders. En hoewel sommigen behoorlijk goed zijn, meestal prima resultaten leveren: het zijn nog steeds taalmodellen, geen juristen.
Wat dat oplevert, is een nieuw soort beroepsvaardigheid. De moderne jurist moet leren samenwerken met een instrument dat nooit helemaal betrouwbaar is. Een digitale stagiair die veel weet, maar altijd toezicht nodig heeft.
De ironie is dat juist juristen, getraind in wantrouwen, nu geneigd zijn AI te geloven omdat ze zo overtuigend formuleert. De echte uitdaging is dus niet technologisch, maar cultureel. Hoe houden we onze eigen twijfel levend in een wereld vol zelfverzekerde algoritmes?
De onderzoekers sloten hun rapport niet af met een waarschuwing, maar met een aanbeveling. De ambitie moet niet zijn om hallucinaties uit te bannen, maar om ze te begrijpen en te beheersen. Alleen dan kan AI een nuttig hulpmiddel zijn.
De vraag blijft wanneer we dat stadium bereiken. Wanneer AI meer is dan een onvoorspelbare stagiair die constant toezicht nodig heeft. Wanneer ze een collega wordt die je werkelijk kunt vertrouwen. Ik vind zelf dat de technologie nog meer ontwikkeld moet zijn met verschillende text mining technieken en koppeling met literatuur voordat chatbots doen wat ze nu al beloven. Tot die tijd geldt de eenvoudige wet die geldt voor zowel legal chatbots als advocaten: gebruik ze, maar geloof hen- nooit op hun woord 🙂
- Bronnen
- Stanford & Yale, Hallucination-Free? Assessing the Reliability of Legal AI Tools, april 2024
- Venturebeat.com: Stanford study finds AI legal research tools prone to hallucinations, juni 2024
- AI on Trial: Legal Models Hallucinate in 1 out of 6 (or More) Benchmarking Queries, mei 2024
- Problematic Stanford GenAI Study Takes Aim at Thomson Reuters + LexisNexis